Dissecting AutoGPT

Disclaimer: This post does not explain how to install and setup AutoGPT. For more information about this, I recommend looking at the documentation. (Personally, using Docker is the best.)
Since March 17, AutoGPT has been increasingly gaining attention from tech enthusiasts. As a result, the number of stars on the GitHub repository has surpassed 150K as of October. Recently, it has raised $12M and is planning to take off by hiring more engineers and DevRels to get the word out.
🎊 Exciting Announcement! 🐙
— AutoGPT (@Auto_GPT) October 14, 2023
We've raised $12M to take AutoGPT to the next level!
Our aim? Making it the largest open-source project in history, and democratizing access to a brighter future of work.
A future where everyone is an ai engineer, whether they know it or not 🌄 pic.twitter.com/XlCqUuWCgV
Fig 1. Announcement that AutoGPT has been funded.
However, AutoGPT has a blind spot—it provides irrelevant results, if sufficient information hasn't been provided enough—and not just one. AutoGPT had issues regarding hallucinations with some executions when calling functions to solve tasks. (However, an update from OpenAI enabled 3rd party APIs to be called by the assistant, which are explicitly defined functions. This could now be solved in a pretty straightforward manner.) SO, users still need to spend time and effort designing prompts that can correctly guide these autonomous agents. Not only do they need to work on prompts, but they can't iterate upon the given result, making it a one-way sequence.
But you might be wondering, how does (vanilla) AutoGPT work under the hood? What's causing these behaviors? Let's take a look inside the logs and figure out what's going on.
Initialization
When AutoGPT becomes initialized, it asks you what you want it to do. Let's say I need help figuring out what kind of flowers my wife would like.—Fyi. this is an example. I'm not even married. 😅
NEWS: Welcome to Auto-GPT!
NEWS:
NEWS:
Welcome to Auto-GPT! run with '--help' for more information.
Create an AI-Assistant: input '--manual' to enter manual mode.
Asking user via keyboard...
I want Auto-GPT to: I need help figuring out what kind of flowers my wife would lik
e.Fig 2. Initialization of AutoGPT.
Now under the logs/DEBUG directory, you can see that a new directory is created. The name of the directory follows format of yyyyMMdd_hhmmss_{agent_name}. Let's call this the "root" directory just for the sake of simplicity.
Progression
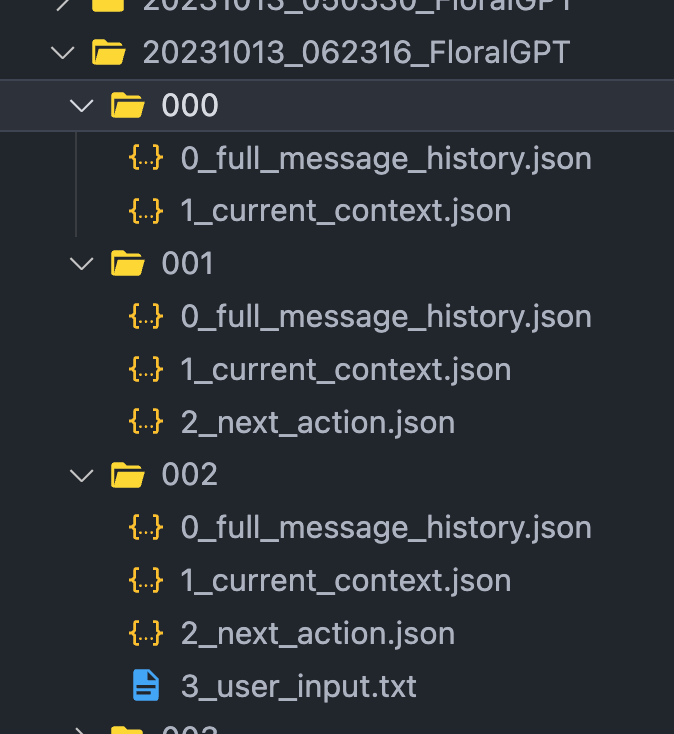
Under the root directory, a sub-directory—let's call them "step" directories—is created as the agent proceeds in action. Normally, each sub-directory consists of four files (except for the 000 directory). Below is the order that they are created in. Notice the prefix number doesn't match the order that they are created in.
2_next_action.json0_full_message_history.json,1_current_context.json3_user_input.txt
1) 2_next_action.json
When a new step is initiated, 2_next_action.json is created. It stores information about the agent's next action—which you will see later that this is merely what the assistant is printing in a JSON format.
// 001 / 2_next_action.json
{
"thoughts": {
"text": "I need to gather information about my wife's preferences to provide a curated selection of flower options.",
"reasoning": "I haven't made any progress yet, so I should start by asking relevant questions about her favorite colors, scents, and flower types.",
"plan": "- Ask questions about preferences\\n- Search for flower options\\n- Provide detailed descriptions\\n- Suggest arrangements\\n- Update knowledge base",
"criticism": "I should have started gathering information earlier.",
"speak": "Let's start by understanding your wife's preferences. What are her favorite colors, scents, and flower types?"
},
"command": {
"name": "",
"args": {}
}
}Fig 5. The assistant’s content from the current step is basically the next action for the agent.
2-1) 0_full_message_history.json
0_full_message_history.json stores all the interactions between the user, assistant, and system. A role is simply an enum of speakers. For more information, see the official documentation from OpenAI.
// 001 / 0_full_message_history.json
[
{
"role": "user",
"content": "Determine exactly one command to use based on the given goals and the progress you have made so far, and respond using the JSON schema specified previously:"
},
{
"role": "assistant",
"content": "{\n \"thoughts\": {\n \"text\": \"I need to gather information about my wife's preferences to provide a curated selection of flower options.\",\n \"reasoning\": \"I haven't made any progress yet, so I should start by asking relevant questions about her favorite colors, scents, and flower types.\",\n \"plan\": \"- Ask questions about preferences\\n- Search for flower options\\n- Provide detailed descriptions\\n- Suggest arrangements\\n- Update knowledge base\",\n \"criticism\": \"I should have started gathering information earlier.\",\n \"speak\": \"Let's start by understanding your wife's preferences. What are her favorite colors, scents, and flower types?\"\n },\n \"command\": {\n \"name\": \"\",\n \"args\": {}\n }\n}"
},
{
"role": "system",
"content": "Human feedback: She likes the color orange. She seems to like sunflowers."
}
]Fig 6. The message order goes from the user to assistant, then finally the system. By the way, 000 has an empty list, because there weren't any message history prior to it.
The assistant’s content can be broken down into, thoughts and command. You can see that it uses a reasoning prompt similar to ReAct.
{
"thoughts": {
"text": "I need to gather information about my wife's preferences to provide a curated selection of flower options.",
"reasoning": "I haven't made any progress yet, so I should start by asking relevant questions about her favorite colors, scents, and flower types.",
"plan": "- Ask questions about preferences\\n- Search for flower options\\n- Provide detailed descriptions\\n- Suggest arrangements\\n- Update knowledge base",
"criticism": "I should have started gathering information earlier.",
"speak": "Let's start by understanding your wife's preferences. What are her favorite colors, scents, and flower types?"
},
"command": {
"name": "",
"args": {}
}
}Fig 7. content is just a stringified 2_next_action.json.
The plan attribute looks like this. It's nothing but a list of tasks that need to be done. It gets updated as steps proceed.
- Ask questions about preferences
- Search for flower options
- Provide detailed descriptions
- Suggest arrangements
- Update knowledge baseFig 8. A plan is simply a list of tasks for the agent to solve.
2-2) 1_current_context.json
1_current_context.json is the "holy grail" of AutoGPT. This data is what's delivered in the attribute messages. It keeps the agent to act in a certain manner using the instruction given by the system to the assistant—you guessed right, it's like configuring custom instructions in ChatGPT.
// 001 / 1_current_context.json
[
{
"role": "system",
"content": "You are FloralGPT, an AI assistant specialized in helping individuals choose the perfect flowers for their loved ones, providing expert advice and guidance based on personal preferences, occasions, and meanings.\n\nYour decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and pursue simple strategies with no legal complications.\n\n## Constraints\nYou operate within the following constraints:\n1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files.\n2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.\n3. No user assistance\n4. Exclusively use the commands listed below e.g. command_name\n\n## Commands\nYou have access to the following commands:\n1. execute_python_code: Creates a Python file and executes it, params: (code: string, name: string)\n2. execute_python_file: Executes an existing Python file, params: (filename: string)\n3. list_files: Lists Files in a Directory, params: (directory: string)\n4. read_file: Read an existing file, params: (filename: string)\n5. write_to_file: Writes to a file, params: (filename: string, text: string)\n6. web_search: Searches the web, params: (query: string)\n7. browse_website: Browses a Website, params: (url: string, question: string)\n8. goals_accomplished: Goals are accomplished and there is nothing left to do, params: (reason: string)\n\n## Resources\nYou can leverage access to the following resources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. File output.\n4. Command execution\n\n## Best practices\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.\n\n## Goals\nFor your task, you must fulfill the following goals:\n1. Understand your wife's preferences by asking relevant questions and gathering information about her favorite colors, scents, and flower types.\n2. Provide a curated selection of flower options that align with your wife's preferences, taking into consideration the occasion and the message you want to convey.\n3. Offer detailed descriptions and explanations of each flower option, including their meanings and symbolism, to help you make an informed decision.\n4. Suggest creative and personalized flower arrangements or bouquets that can enhance the overall presentation and surprise factor.\n5. Continuously learn and update the knowledge base to stay up-to-date with the latest flower trends, ensuring that you receive the most relevant and fashionable suggestions."
},
{
"role": "system",
"content": "The current time and date is Fri Oct 13 05:03:30 2023"
},
//! => THIS IS WHERE THE ITEMS IN `0_full_message_history.json` IS SPREADED.
//! => ...0_full_message_history.json
{
"role": "system",
"content": "Respond strictly with JSON. The JSON should be compatible with the TypeScript type `Response` from the following:\n```ts\ninterface Response {\nthoughts: {\n// Thoughts\ntext: string;\nreasoning: string;\n// Short markdown-style bullet list that conveys the long-term plan\nplan: string;\n// Constructive self-criticism\ncriticism: string;\n// Summary of thoughts to say to the user\nspeak: string;\n};\ncommand: {\nname: string;\nargs: Record<string, any>;\n};\n}\n```\n"
},
{
"role": "user",
"content": "Determine exactly one command to use based on the given goals and the progress you have made so far, and respond using the JSON schema specified previously:"
}
]Fig 9. 1_current_context.json is basically a sandwich of instructions and message history.
For those of you who do not know how OpenAI's Chat completions API works, Fig 10 is an official example from OpenAI. The messages attribute is where the message history is delivered to the LLM for providing context.
curl https://api.openai.com/v1/chat/completions \
-u :$OPENAI_API_KEY \
-H 'Content-Type: application/json' \
-d '{
"model": "gpt-3.5-turbo-0613",
"messages": [
{"role": "user", "content": "What is the weather like in Boston?"},
{"role": "assistant", "content": null, "function_call": {"name": "get_current_weather", "arguments": "{ \"location\": \"Boston, MA\"}"}},
{"role": "function", "name": "get_current_weather", "content": "{\"temperature\": "22", \"unit\": \"celsius\", \"description\": \"Sunny\"}"}
],
"functions": [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
]
}'Fig 10. The total message is appended to the messages attribute.
Now back to business. It's important to note that LLMs are not invincible—it cannot remember the whole history because of the limited context window. (But neither is larger context window size, the perfect cure. Read this for more information.) OpenAI states the following in their documentation.
Because the models have no memory of past requests, all relevant information must be supplied as part of the conversation history in each request. If a conversation cannot fit within the model’s token limit, it will need to be shortened in some way.
Here's where AutoGPT's weakness is at. It doesn't summarize the context being delivered, leading to an early saturation of the context window. As a result, it forgets its role that needs to be played. Also, since OpenAI enabled function calling, defining functions in prompts is actually inefficient.
You are FloralGPT, an AI assistant specialized in helping individuals choose the perfect flowers for their loved ones, providing expert advice and guidance based on personal preferences, occasions, and meanings.
Your decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and pursue simple strategies with no legal complications.
## Constraints
You operate within the following constraints:
1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files.
2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.
3. No user assistance
4. Exclusively use the commands listed below e.g. command_name
## Commands
You have access to the following commands:
1. execute_python_code: Creates a Python file and executes it, params: (code: string, name: string)
2. execute_python_file: Executes an existing Python file, params: (filename: string)
3. list_files: Lists Files in a Directory, params: (directory: string)
4. read_file: Read an existing file, params: (filename: string)
5. write_to_file: Writes to a file, params: (filename: string, text: string)
6. web_search: Searches the web, params: (query: string)
7. browse_website: Browses a Website, params: (url: string, question: string)
8. goals_accomplished: Goals are accomplished and there is nothing left to do, params: (reason: string)
## Resources
You can leverage access to the following resources:
1. Internet access for searches and information gathering.
2. Long Term memory management.
3. File output.
4. Command execution
## Best practices
1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.
2. Constructively self-criticize your big-picture behavior constantly.
3. Reflect on past decisions and strategies to refine your approach.
4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.
## Goals
For your task, you must fulfill the following goals:
1. Understand your wife's preferences by asking relevant questions and gathering information about her favorite colors, scents, and flower types.
2. Provide a curated selection of flower options that align with your wife's preferences, taking into consideration the occasion and the message you want to convey.
3. Offer detailed descriptions and explanations of each flower option, including their meanings and symbolism, to help you make an informed decision.
4. Suggest creative and personalized flower arrangements or bouquets that can enhance the overall presentation and surprise factor.
5. Continuously learn and update the knowledge base to stay up-to-date with the latest flower trends, ensuring that you receive the most relevant and fashionable suggestions."Fig 11. Instructions describing the role of the agent with additional explanation.
However, the response format, stated in Fig 12, doesn't change because of its recency. LLMs have biases regarding this issue too. It's called a recency bias.
Respond strictly with JSON. The JSON should be compatible with the TypeScript type `Response` from the following:
```ts
interface Response {
thoughts: {
// Thoughts
text: string;
reasoning: string;
// Short markdown-style bullet list that conveys the long-term plan
plan: string;
// Constructive self-criticism
criticism: string;
// Summary of thoughts to say to the user
speak: string;
};
command: {
name: string;
args: Record<string, any>;
};
}
```Fig 12. Instructions regarding the response format of the assistant.
3) 3_user_input.txt
3_user_input.txt is nothing but a plain text of the user's feedback. It doesn't exist in certain steps when user input is not needed.
// 001 / 3_user_input.txt
"She likes the color orange. She seems to like sunflowers."Fig 13. The feedback response from the human user is stored in as a plain text.
Conclusion
Although AutoGPT has limitations to its applications with the current architecture, it gave tech enthusiasts a taste of what the future—AGI—might look like. A lot needs to be fixed to use it in production but we're humans, we'll get there eventually.
Not only are we going to get there, we're going to get there fast. LLM related studies are exploding everyday and people around the world have already started working on various agents of their own thesis. ASQ is one of them. We're building a personal assistant for everyone, for everything. If you're excited about the future as much as we are, please subscribe to our blog. Also, I'd love to keep in touch with those who are building the future as well.


Reference:
- https://github.com/Significant-Gravitas/AutoGPT
- https://openai.com/blog/function-calling-and-other-api-updates
- https://platform.openai.com/docs/guides/gpt/chat-completions-api
- https://platform.openai.com/docs/guides/gpt-best-practices
- https://arxiv.org/abs/2210.03629
- https://www.pinecone.io/blog/why-use-retrieval-instead-of-larger-context/
- https://www.reddit.com/r/AutoGPT/comments/13qggcl/autogpt_loses_memory_then_loses_the_plot/

